YOLO 快速入门:从图像到目标检测的第一步
一、YOLO 介绍
1.1 YOLO 是什么?
YOLO,全称 You Only Look Once,是一种实时目标检测算法,它可以在一张图像中快速识别多个目标的位置和类别。YOLO 以其高效和实时性能广泛应用于安防、自动驾驶、智能监控等领域。
1.2 YOLO 的核心思想
传统的目标检测方法通常分为两个阶段:
- 先提取候选区域(Region Proposals);
- 再对每个区域进行分类。
而 YOLO 则采用单阶段检测的方式,直接把目标检测当成一个回归问题来处理:
- 输入一张图像;
- 网络直接输出每个目标的:
- 类别(比如:人、狗、车);
- 位置信息(边界框坐标);
- 置信度(置信评分)。
1.3 YOLO 的演进版本
YOLO 系列已经发展了多个版本:
| 版本 | 特点 |
|---|---|
| YOLOv1 | 最初版本,速度快但准确度一般 |
| YOLOv3 | 多尺度检测,引入残差结构 |
| YOLOv4 | 性能全面提升,加入大量优化技巧 |
| YOLOv5 | 用 PyTorch 编写,轻量、开源活跃 |
| YOLOv6/7/8 | 不同团队推出,精度和速度进一步优化 |
💡 新手推荐使用 YOLOv5 或 YOLOv8,文档丰富、社区活跃、支持导出 ONNX 等多种部署格式。
二、尝试使用YOLO(快速入门)
以YOLO V5为例,这里我使用uv来管理Python虚拟环境(请自行提前安装uv和python 注意:Python>=3.8.0 ):
克隆 YOLOv5 仓库 并安装依赖环境:
git clone https://github.com/ultralytics/yolov5
cd yolov5
uv venv
.venv\Scripts\activate
uv pip install -r requirements.txt如下图:
下载得到的Yolo5文件夹目录如下:
其中重要的文件解释如下、做了解即可:
yolov5/ # YOLOv5 项目根目录
├── classify/ # 分类任务相关代码
├── data/ # 数据集配置文件 (coco128.yaml 等)
├── models/ # 模型结构定义 (yolov5s.yaml 等)
├── segment/ # 分割任务相关代码
├── utils/ # 工具函数 (增强、NMS、日志、绘图等)
├── detect.py # 推理脚本 (图片/视频/摄像头检测)
├── train.py # 训练脚本
├── val.py # 验证脚本 (mAP 等指标)
├── export.py # 模型导出脚本 (ONNX, TensorRT, CoreML...)
├── hubconf.py # 允许 torch.hub.load 加载模型
├── benchmarks.py # 性能基准测试
├── requirements.txt # Python 依赖库清单
├── pyproject.toml # 项目配置 (构建/依赖信息)
├── LICENSE # 开源许可证 (AGPL-3.0)
├── README.md # 项目说明 (英文)
├── README.zh-CN.md # 项目说明 (中文)
├── CONTRIBUTING.md # 贡献指南
├── CITATION.cff # 学术引用文件
├── .git/ # Git 版本控制文件夹
├── .github/ # GitHub 配置 (CI/CD workflows)
├── .gitignore # Git 忽略规则
├── .dockerignore # Docker 忽略规则
├── .venv/ # 虚拟环境 (本地生成,不是源码自带)下面我们使用推理脚本 detect.py 来进行目标检测的初次尝试,官方文档里给的指令很清晰,有下面这些:
python detect.py --weights yolov5s.pt --source 0 # webcam
python detect.py --weights yolov5s.pt --source image.jpg # image
python detect.py --weights yolov5s.pt --source video.mp4 # video
python detect.py --weights yolov5s.pt --source screen # screenshot
python detect.py --weights yolov5s.pt --source path/ # directory
python detect.py --weights yolov5s.pt --source list.txt # list of images
python detect.py --weights yolov5s.pt --source list.streams # list of streams
python detect.py --weights yolov5s.pt --source 'path/*.jpg' # glob pattern
python detect.py --weights yolov5s.pt --source 'https://youtu.be/LNwODJXcvt4' # YouTube video
python detect.py --weights yolov5s.pt --source 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream这里我们使用第一种来加载我们的电脑摄像头:
使用命令(这里的--source 0 值摄像头编号,这里我有多个摄像头,我使用1号):
python detect.py --weights yolov5s.pt --source 1运行后效果如下:
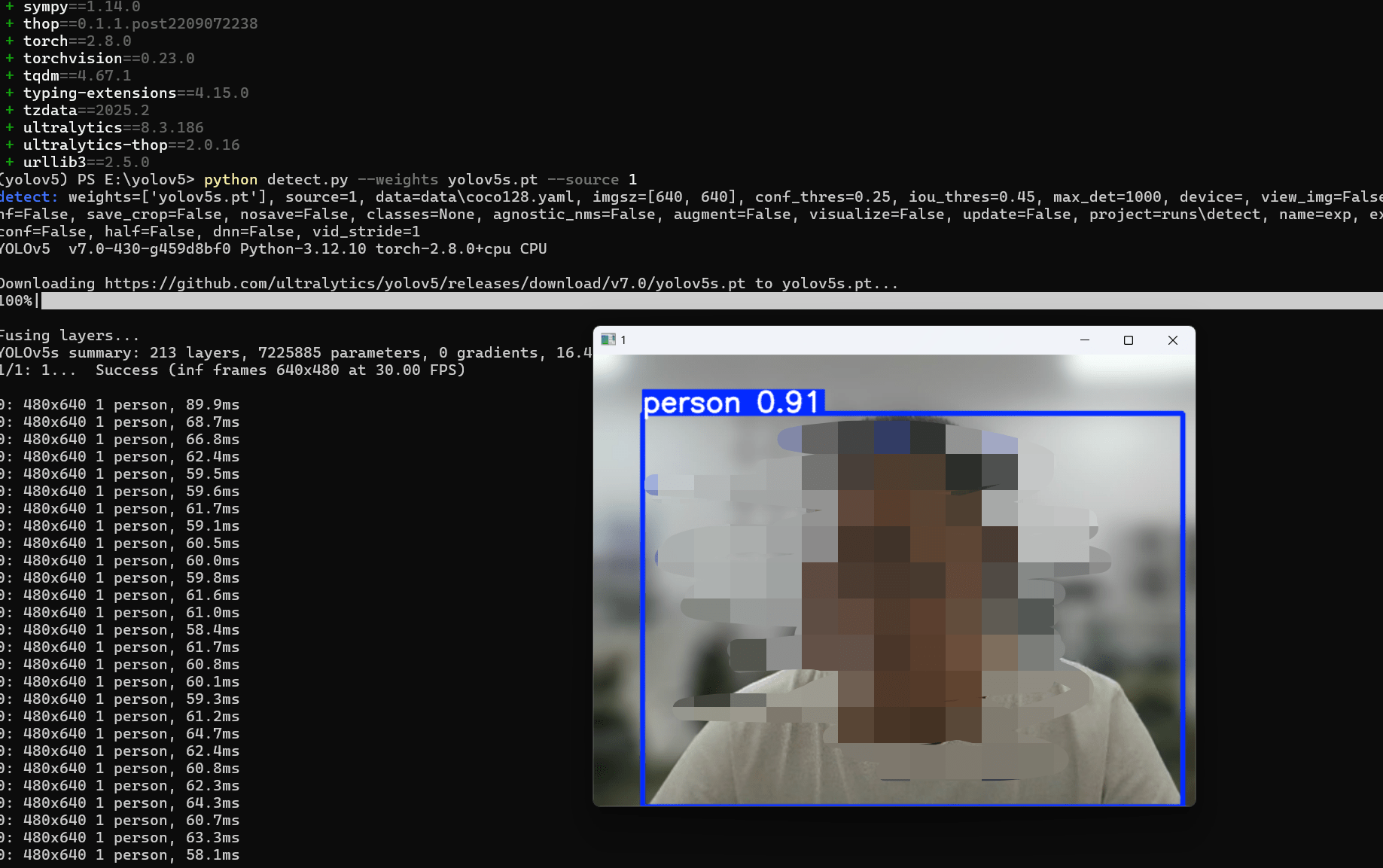
这样我们就完成了一次目标检测的尝试,我们也可以使用本地图片进行检测,将--source 的参数改为本地图片路径即可,比如--source img.jpg, 检测完成的结构会输出在目录下面的runs文件夹内,便于再次查看。
到这里我们就完成了Yolo的基本使用,下面我们尝试自行训练模型,来识别真正想识别的东西。
二、获取一个可以用于训练的数据集
2.1 什么是目标检测数据集?
目标检测数据集包含两个核心部分:
- 图像文件:包含待检测目标的图片
- 标注文件:描述图像中目标的位置和类别信息
2.2 常见数据集格式
COCO 格式
- 特点:JSON 格式,适合复杂场景
- 结构:
dataset/ ├── images/ # 图像文件夹 │ ├── train/ │ └── val/ └── annotations/ # 标注文件夹 ├── instances_train.json └── instances_val.json
YOLO 格式
- 特点:每张图片对应一个 txt 标注文件
- 结构:
dataset/ ├── images/ │ ├── train/ │ └── val/ └── labels/ ├── train/ └── val/ - 标注格式:
class_id center_x center_y width height- 所有坐标都是相对于图像尺寸的比例值(0-1)
Pascal VOC 格式
- 特点:XML 格式,结构清晰
- 结构:
dataset/ ├── JPEGImages/ # 图像文件 ├── Annotations/ # XML标注文件 └── ImageSets/ # 数据集划分信息
2.3 常用公开数据集
| 数据集名称 | 类别数 | 图像数量 | 特点 |
|---|---|---|---|
| COCO | 80 | 330K | 复杂场景,多目标 |
| Pascal VOC | 20 | 20K | 经典数据集,入门首选 |
| Open Images | 600+ | 9M | 大规模,类别丰富 |
| ImageNet | 1000+ | 14M | 主要用于分类,也有检测版本 |
2.4 获取开源数据集用于训练
网上有很多公开的数据集可以选择,这里我使用 https://universe.roboflow.com/ 这个网站:
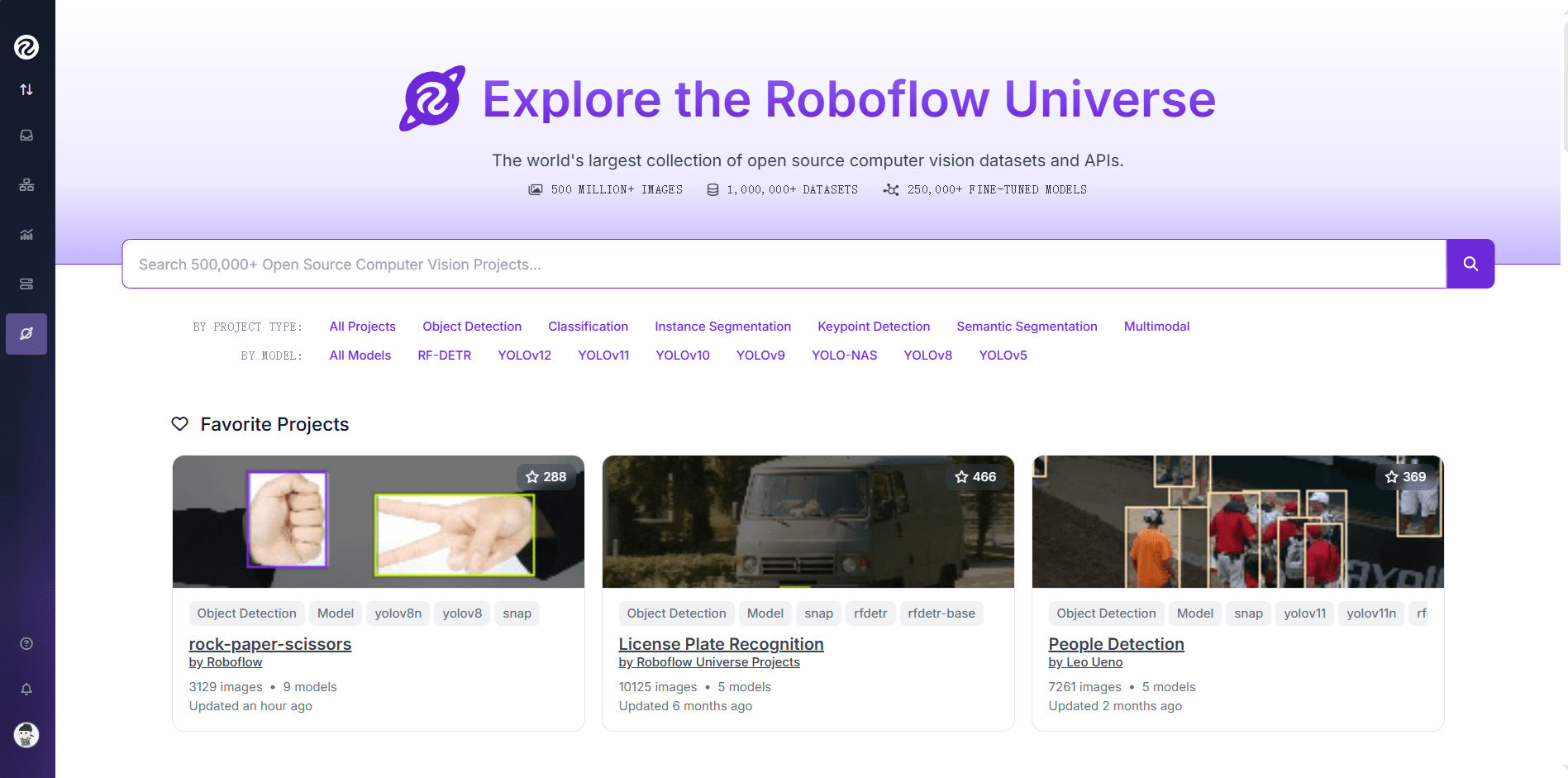
这里可以下载众多开源数据集,甚至是训练好的模型,为了快速上手,我们从一个现成的数据集开始:
这里我们使用这个: https://universe.roboflow.com/selma-vurgun/gul/dataset/1 这个数据集,一个玫瑰花识别的数据集
下载YOLOV5格式:
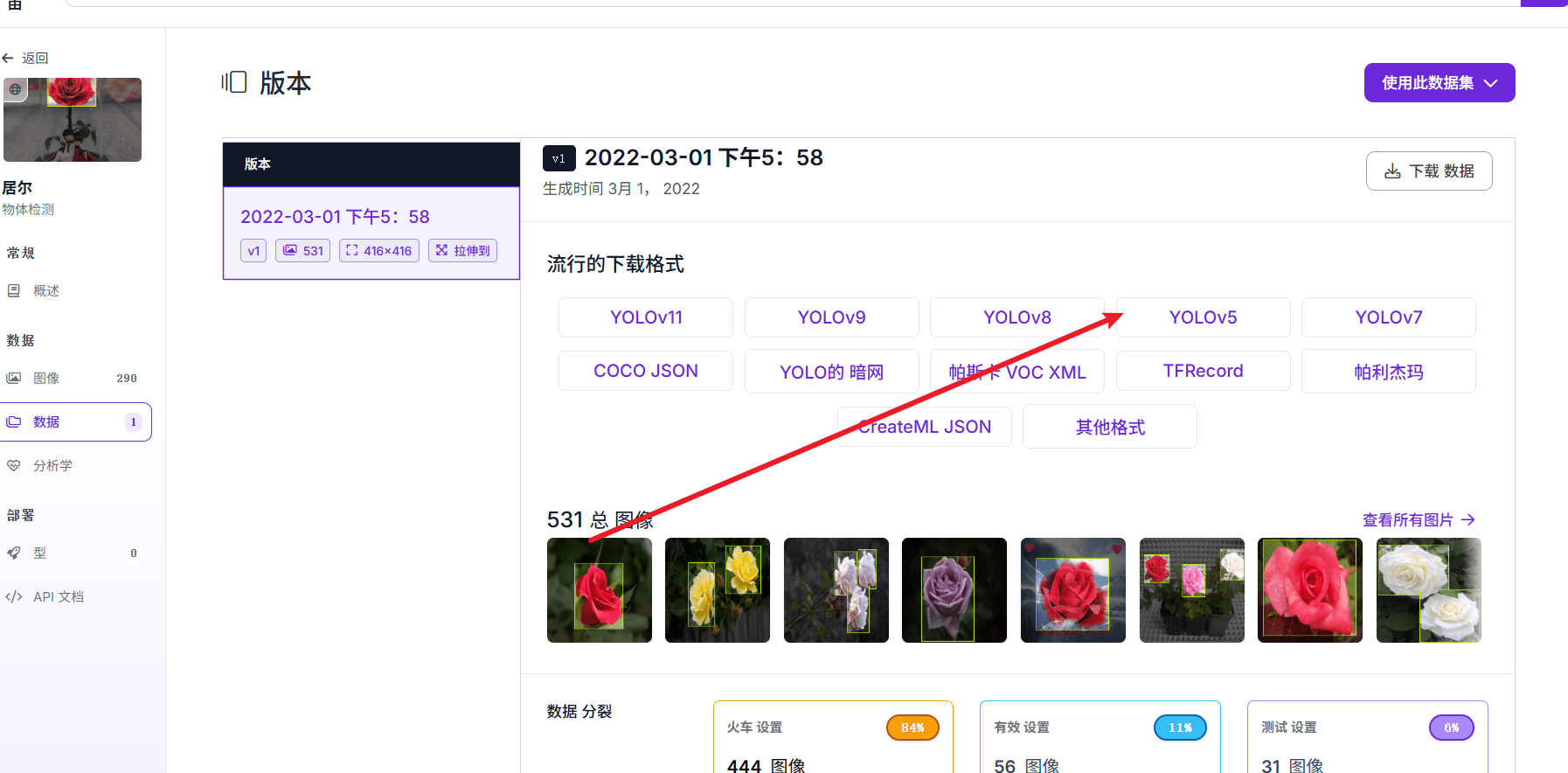
下载所有图像到本地:
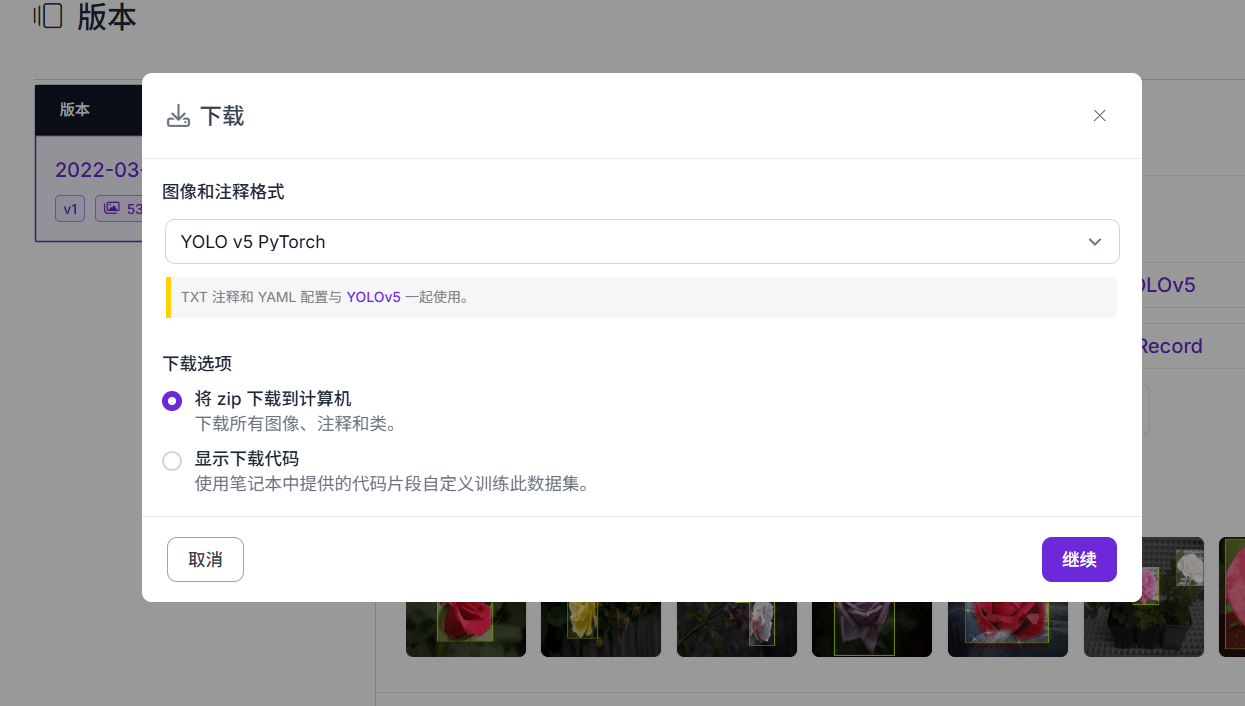
下载好后如下:

可以查看data.yaml的内容如下:
train: ../train/images
val: ../valid/images
nc: 1
names: ['Rose']主要用于标明对应训练集,验证集的位置,物品种类1,名称为玫瑰。
将数据集放到YOLO5文件夹里,命名为dataset (放其他地方也行),如下:
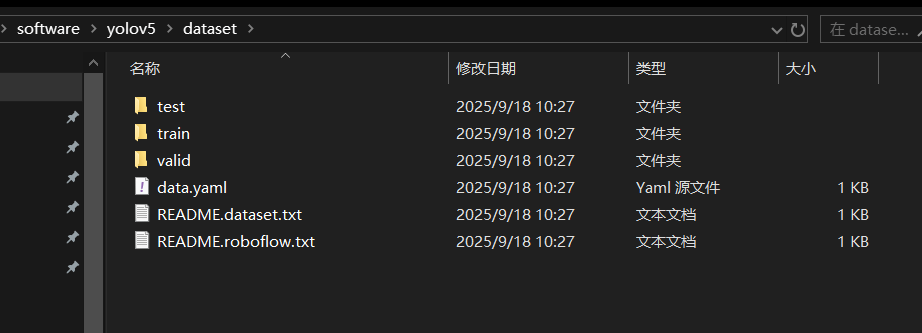
三、通过数据集训练模型
3.1 准备
首先修改数据集里的data.yaml文件
train: ./dataset/train/images
val: ./dataset/valid/images
nc: 1
names: ['Rose']确认好文件的位置,labels的目录不用写进去,会自动识别
如果有GPU,可以使用下面的命令确认GPU是否可用:
python -c "import torch; print(torch.cuda.is_available())"如下: 
如果输出 True,说明可以用 GPU 训练。反之,可能是需要按照GPU版本的PyTorch,具体如何安装,请教AI即可。
3.2 进行训练
在 YOLOv5 根目录运行以下命令:
.venv\Scripts\activate
python train.py --img 416 --batch 8 --epochs 100 --data dataset/data.yaml --weights yolov5s.pt --device 0 --cache命令说明:
uv run python train.py
用 uv 运行虚拟环境里的 Python,执行 YOLOv5 的训练脚本 train.py。
--img 416
输入图像的大小,训练时所有图片会被缩放到 416x416。
默认是 640,但你显卡只有 4GB 显存,所以改小一点,能省显存。
--batch 8
每个训练批次处理 8 张图片。
批次越大,训练越稳定,但显存占用也更高。
在 4GB 显卡上,8 是比较稳妥的选择。
--epochs 100
训练 100 个完整的迭代周期(epoch = 数据集完整走一遍)。
一般小数据集几十个 epoch 就够,大数据集可能要上百。
--data dataset/data.yaml
指定数据集配置文件(类别数量、类别名、训练/验证图片路径等都在里面)。
你之前修改过的 data.yaml 就是这个。
--weights yolov5s.pt
预训练模型权重,yolov5s.pt 是 YOLOv5 最小的轻量化版本(s = small)。
用预训练权重做迁移学习,能加快收敛速度,效果也更好。
--device 0
指定使用第 0 号 GPU(如果你有多块 GPU,可以用 --device 1、--device 0,1 等)。
如果写成 cpu,就是强制用 CPU。训练显示如下,总耗时大概 45 分钟:
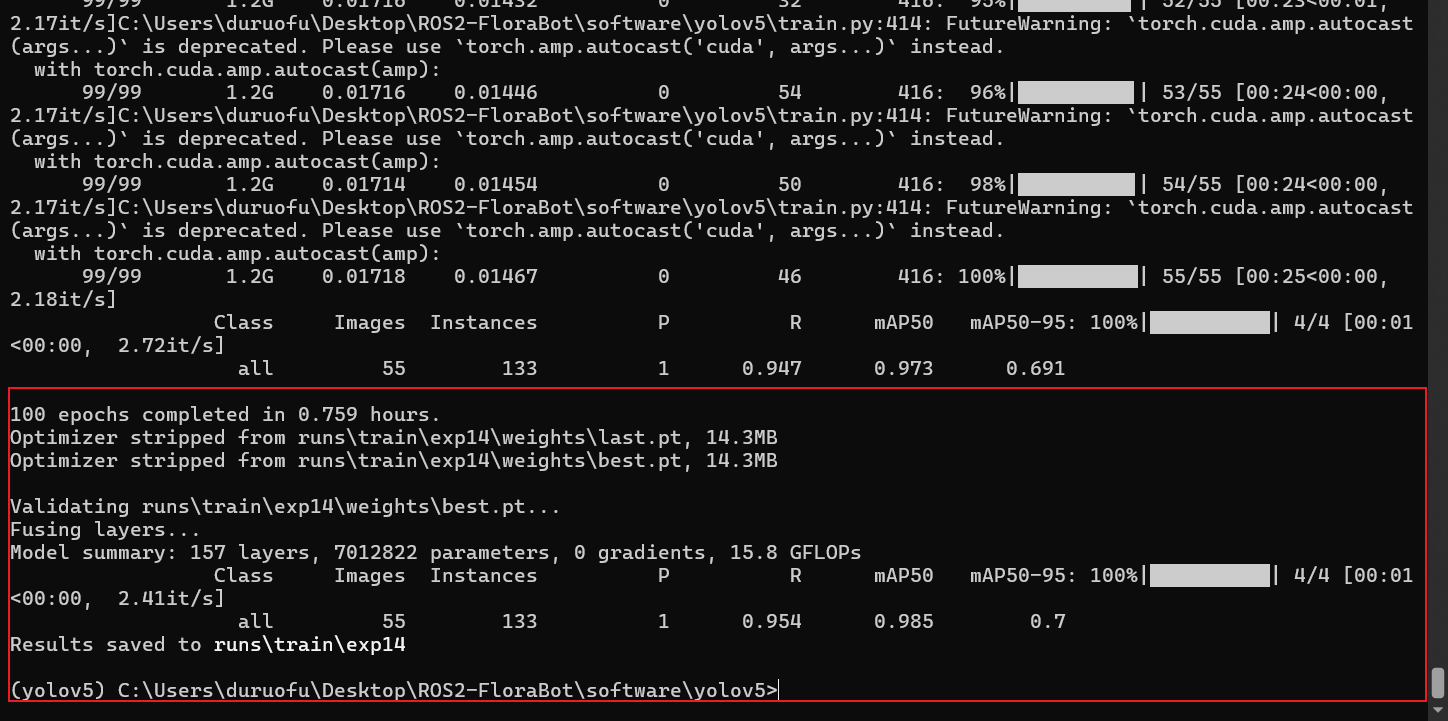
可以看到对应的模型已经保存到了:
Optimizer stripped from runs\train\exp14\weights\last.pt, 14.3MB
Optimizer stripped from runs\train\exp14\weights\best.pt, 14.3MB其中:
last.pt:最后一次训练迭代的权重best.pt:在验证集上效果最好的权重(通常推理时用这个)
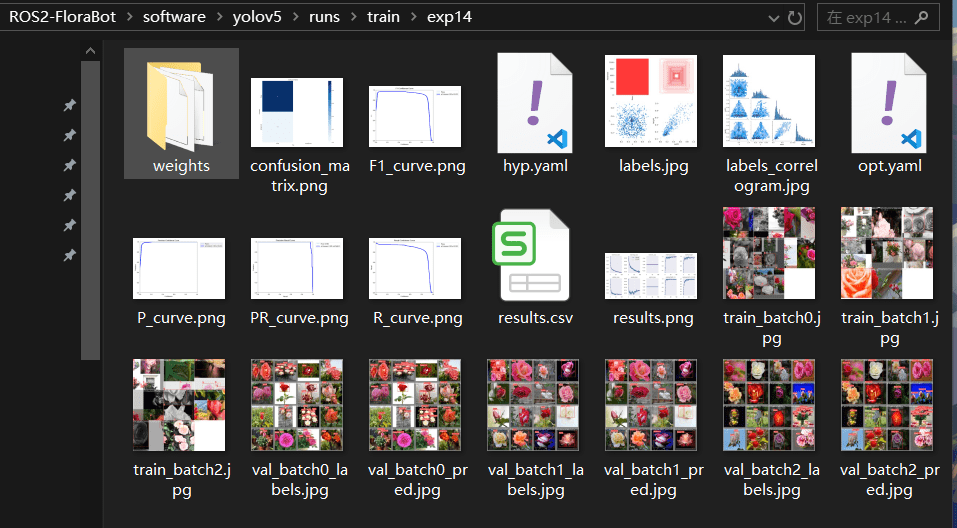
3.2 查看训练结果
训练完成后,输出目录会有:
weights/last.pt和weights/best.pt:模型权重文件results.png:训练过程的损失曲线和 mAPconfusion_matrix.png:混淆矩阵
在训练结束后,可以使用 detect.py 脚本对图片、视频或摄像头进行推理测试。
常用参数说明:
--weights:指定模型权重路径(通常用 best.pt)- --source :输入源,可以是图片、视频、文件夹,甚至是摄像头
- img.jpg → 单张图片
- data/images/ → 文件夹下所有图片
- 0 → 默认摄像头
- video.mp4 → 本地视频
- --conf-thres :置信度阈值(默认 0.25)
- --iou-thres :NMS 的 IOU 阈值(默认 0.45)
- --device :推理设备(0 表示 GPU0,cpu 表示用 CPU)
这里我们从测试集里找一张图片检验模型:
.venv\Scripts\activate
python detect.py --weights runs/train/rose_exp/weights/best.pt --source dataset/test/images/183_jpg.rf.1944a2a60202aa6f151acaf4bd413480.jpg运行结果如下:
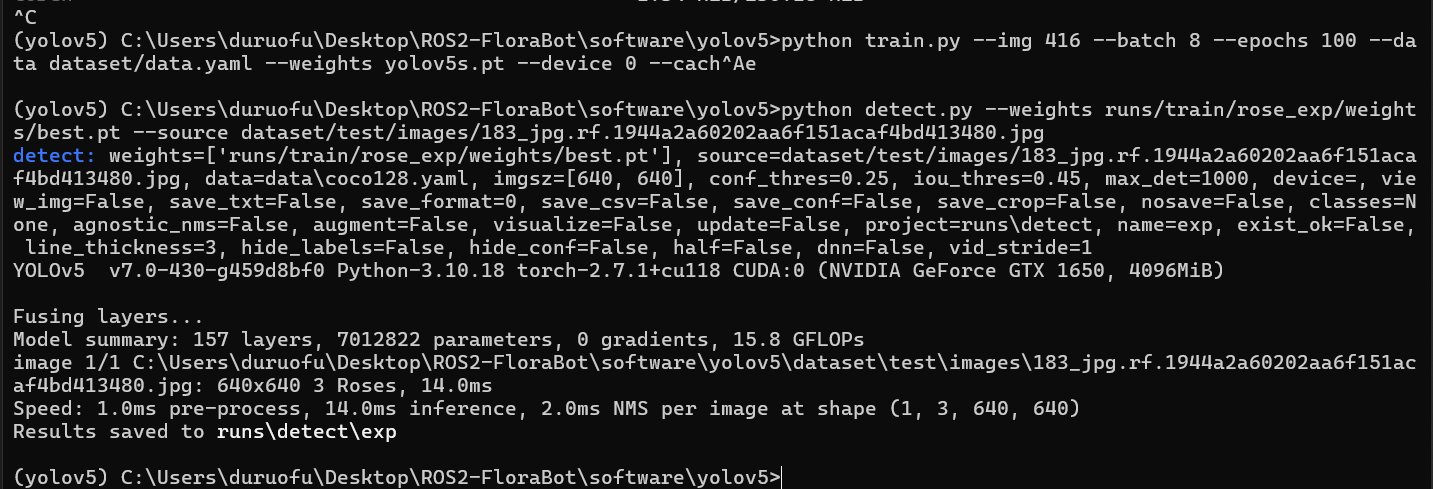
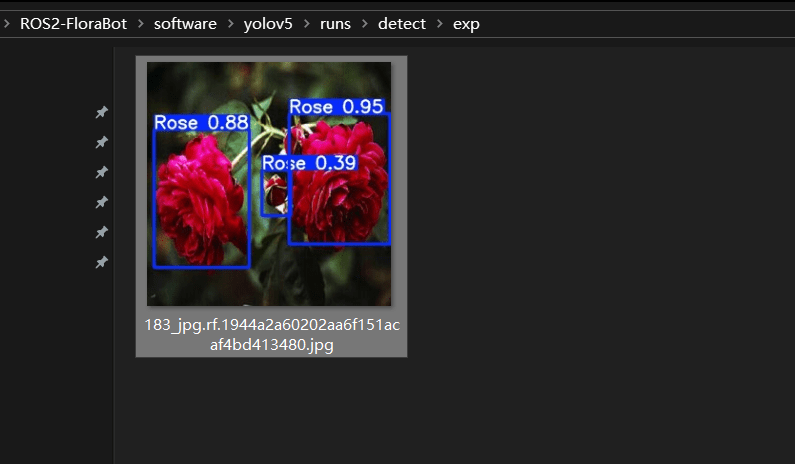
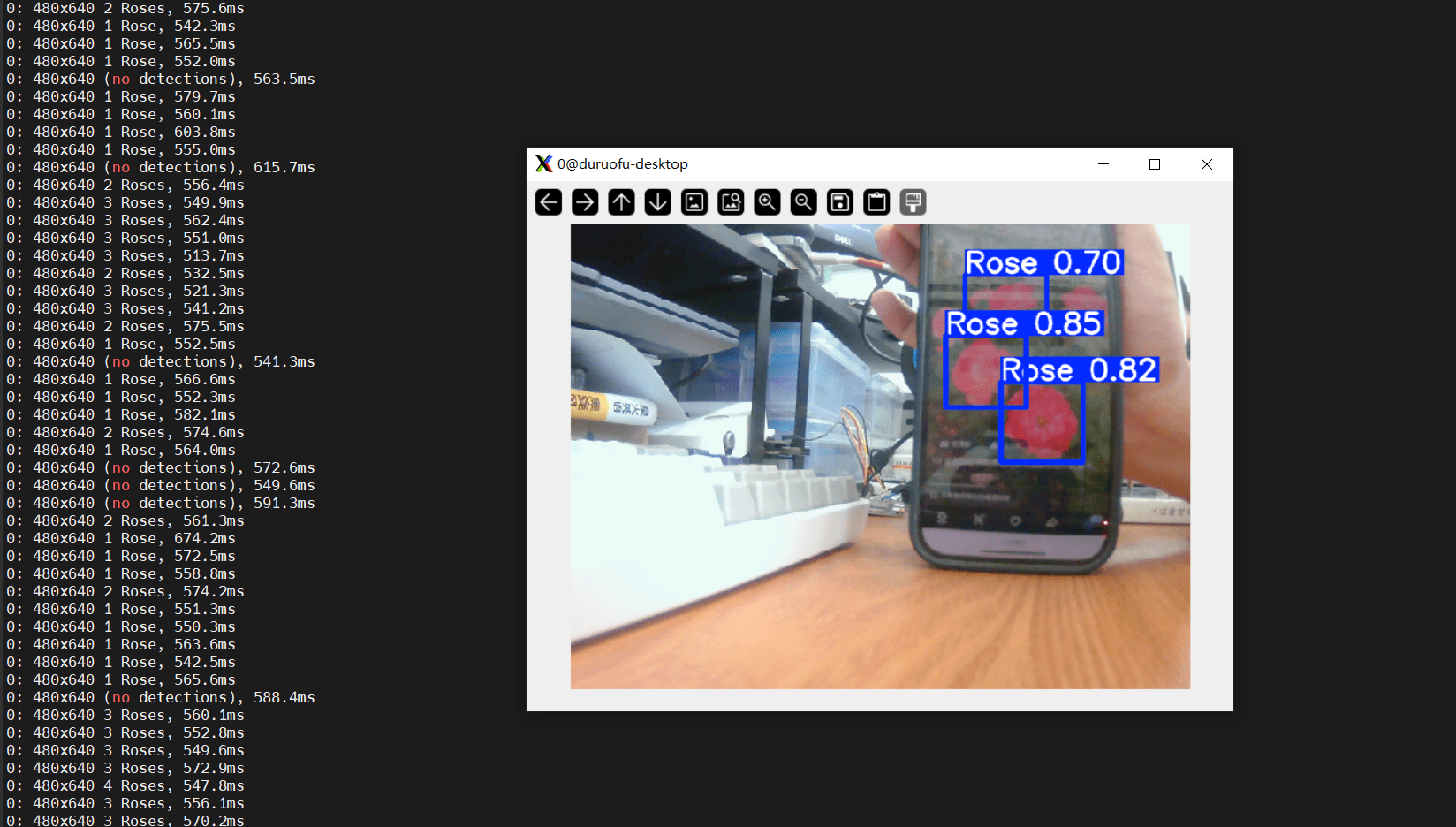
可以看到已经成功运行了,并且输出结果到目录下了,我们也可以使用摄像头进行检测:
.venv\Scripts\activate
python detect.py --weights runs/train/rose_exp/weights/best.pt --source 2效果如下:
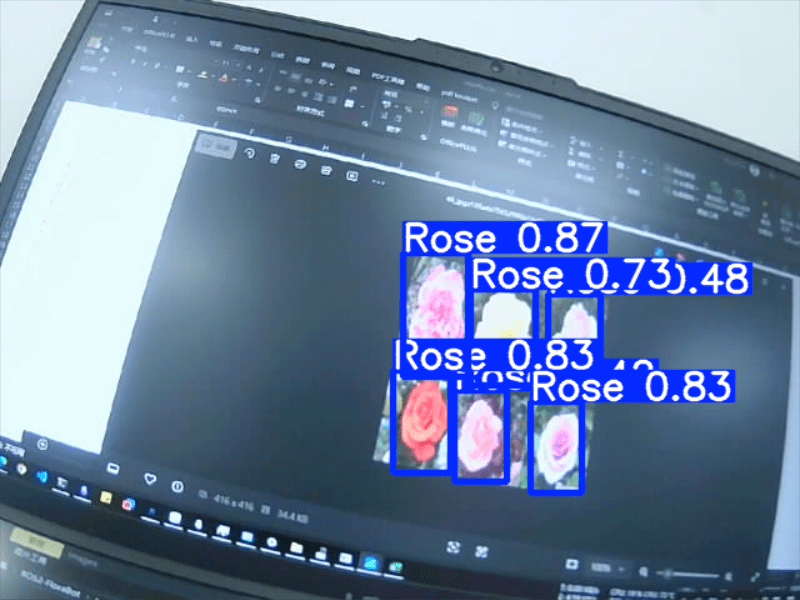
三、在树莓派部署模型
3.1 直接用 PyTorch 部署(最简单,但性能一般)
在树莓派上安装下载并安装YOLO5:
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
sudo apt install python3-venv -y
python3 -m venv yolov5-venv
source yolov5-venv/bin/activate
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple然后把 PC 上训练好的 best.pt 复制到树莓派 yolov5 目录下。
运行推理:
source yolov5-venv/bin/activate
python3 detect.py --weights best.pt --source 0 --device cpu这个时候可能会报错:
NotImplementedError: cannot instantiate 'WindowsPath' on your system我们可以修改detect.py,在文件最起前面添加:
import platform
import pathlib
if platform.system() != 'Windows':
pathlib.WindowsPath = pathlib.PosixPath把 pathlib.WindowsPath 替换成 pathlib.PosixPath。 运行效果如图所示:
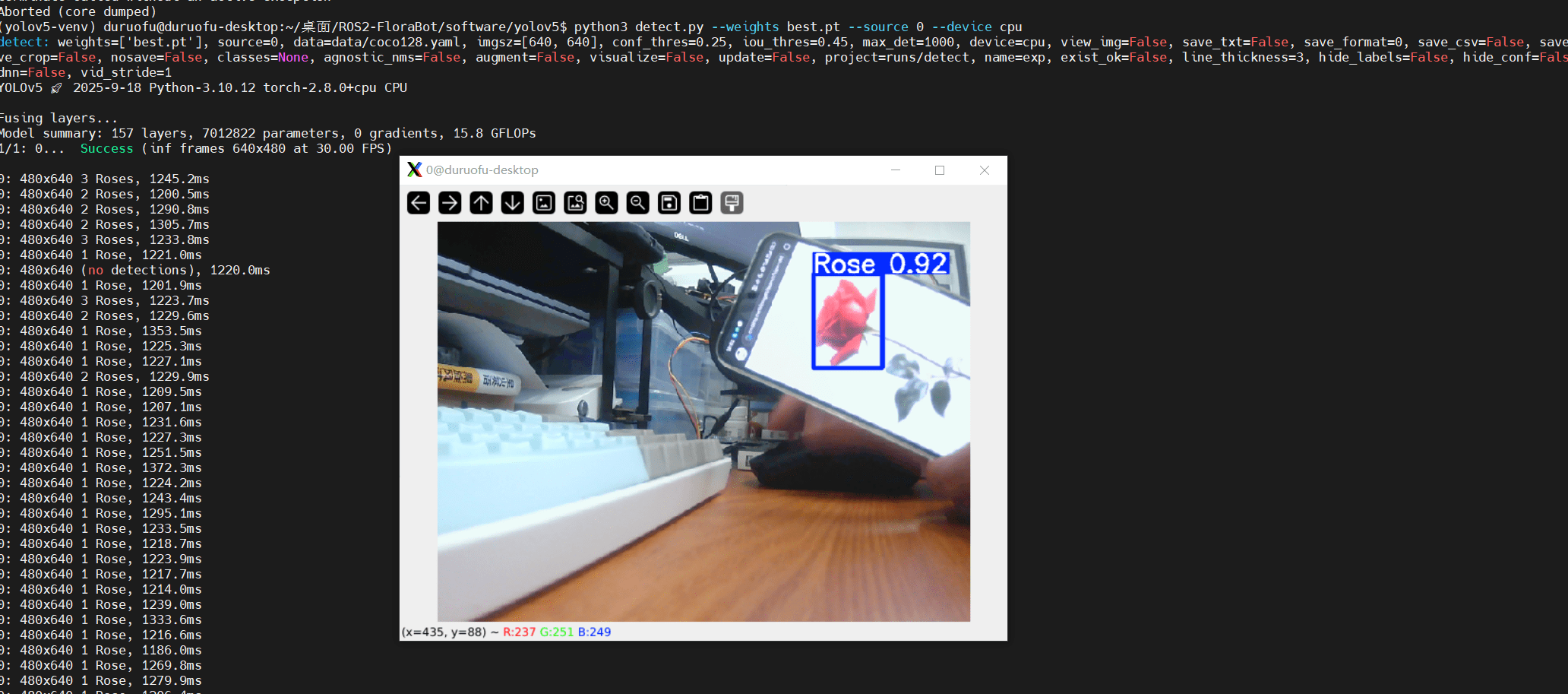
但是可以看到,每次推理的耗时在1.2 秒左右,实在是太慢了,如何进一步提升速度呢。
我们使用使用更轻量的模型 yolov5n,重新训练一个模型:
.venv\Scripts\activate
python train.py --img 416 --batch 8 --epochs 100 --data dataset/data.yaml --weights yolov5n.pt --device 0 --cache这样推理时间就减小一半,来到了500ms: