什么是大语言模型(LLMs)?
你有没有想过,为什么ChatGPT能够和你聊天、写代码、翻译文章,甚至帮你写诗?这背后的秘密就是"大语言模型"。
开宗名义:大语言模型(Large Language Models)指的是参数数量庞大、结构复杂的深度学习模型。参数数量通常从百万到数十亿,甚至更多。
一、什么是“大模型”
1.1 定义
大语言模型,顾名思义,就是参数数量特别多的AI模型:
- 以参数规模为主指标(通常是10亿参数以上)
- 一类通过海量数据训练的通用型神经网络模型
- 通常采用 Transformer 架构
传统的AI模型就像专业技工,一个模型只会做一件事。但大语言模型就像是个全才,能够处理多种不同的任务。
1.2 特点
大语言模型有几个让人惊叹的特点:
- 通用性:一个模型适配多种任务(对话、翻译、写作、代码等)
- 上下文理解能力强:可处理大篇幅上下文
- "零样本"或"少样本"学习:不需要大量标注数据就能执行任务
- 生成能力强:可生成文本、代码、图像等
最神奇的是,你只需要给它几个例子(甚至不给例子),它就能学会新任务。这就像你告诉一个聪明的朋友"帮我把这段话改成诗歌风格",他立马就能理解并做到。
1.3 与传统模型的区别
让我们用一个表格来对比一下:
| 对比项 | 传统小模型 | 大模型(如GPT) |
|---|---|---|
| 数据依赖 | 任务特定数据 | 通用数据,海量训练 |
| 参数量 | 万到百万级 | 亿到千亿级 |
| 能力 | 针对单一任务 | 多任务、多语言、多模态 |
| 推理能力 | 弱 | 强(如链式思考、工具调用) |
| 训练时间与资源 | 少 | 非常高(需要GPU集群) |
简单来说,就是从"专业技工"进化成了"博士生导师"的区别。
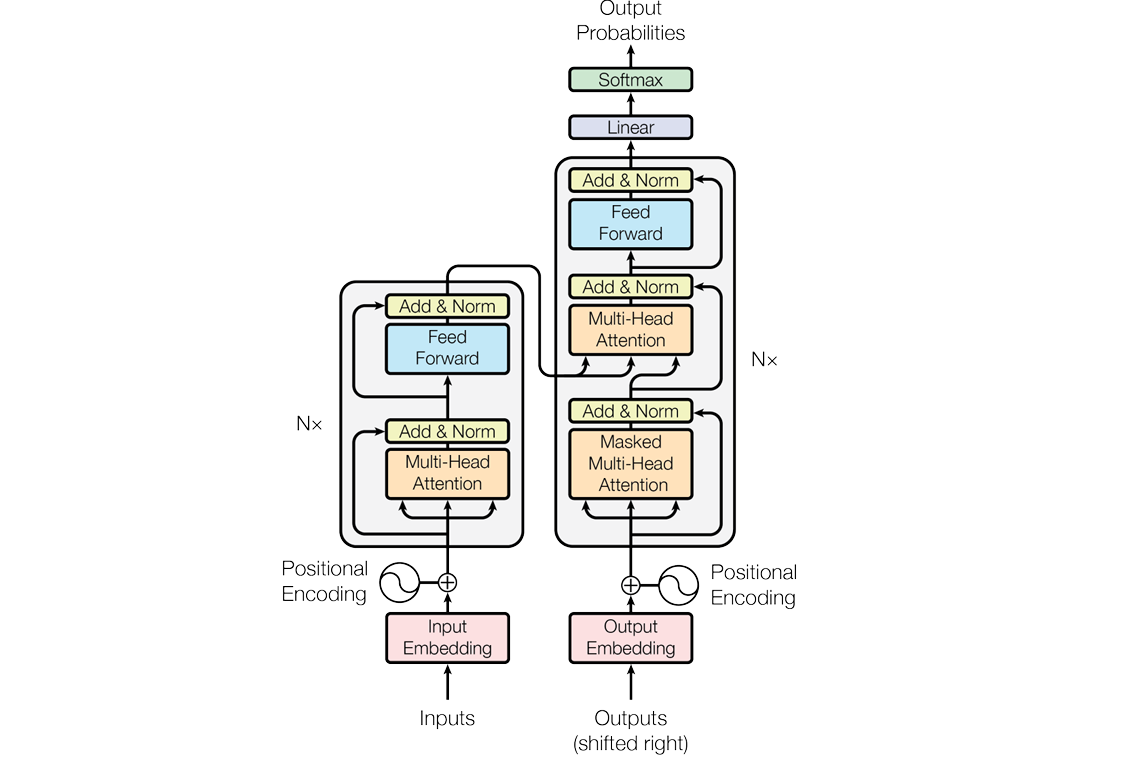
Transformer架构
大部分大语言模型都基于一个叫做Transformer的架构。这个名字听起来很酷,但其实原理并不复杂。
想象你在读一本小说:
- 你不会孤立地理解每个词
- 而是会联系上下文来理解整个故事
- 前面的情节会影响你对后面内容的理解
Transformer就是模仿了这种阅读方式。它有一个叫做"注意力机制"的功能,能够同时关注文本中的所有词语,理解词语之间的关系。