YOLO 入门:从图像到目标检测的第一步
一、YOLO 介绍
1.1 YOLO 是什么?
YOLO,全称 You Only Look Once,是一种实时目标检测算法,它可以在一张图像中快速识别多个目标的位置和类别。YOLO 以其高效和实时性能广泛应用于安防、自动驾驶、智能监控等领域。
1.2 YOLO 的核心思想
传统的目标检测方法通常分为两个阶段:
- 先提取候选区域(Region Proposals);
- 再对每个区域进行分类。
而 YOLO 则采用单阶段检测的方式,直接把目标检测当成一个回归问题来处理:
- 输入一张图像;
- 网络直接输出每个目标的:
- 类别(比如:人、狗、车);
- 位置信息(边界框坐标);
- 置信度(置信评分)。
1.3 YOLO 的演进版本
YOLO 系列已经发展了多个版本:
| 版本 | 特点 |
|---|---|
| YOLOv1 | 最初版本,速度快但准确度一般 |
| YOLOv3 | 多尺度检测,引入残差结构 |
| YOLOv4 | 性能全面提升,加入大量优化技巧 |
| YOLOv5 | 用 PyTorch 编写,轻量、开源活跃 |
| YOLOv6/7/8 | 不同团队推出,精度和速度进一步优化 |
💡 新手推荐使用 YOLOv5 或 YOLOv8,文档丰富、社区活跃、支持导出 ONNX 等多种部署格式。
二、尝试使用YOLO(快速入门)
以YOLO V5为例,这里我使用uv来管理Python虚拟环境(请自行提前安装uv和python 注意:Python>=3.8.0 ):
克隆 YOLOv5 仓库 并安装依赖环境:
git clone https://github.com/ultralytics/yolov5
cd yolov5
uv venv
.venv\Scripts\activate
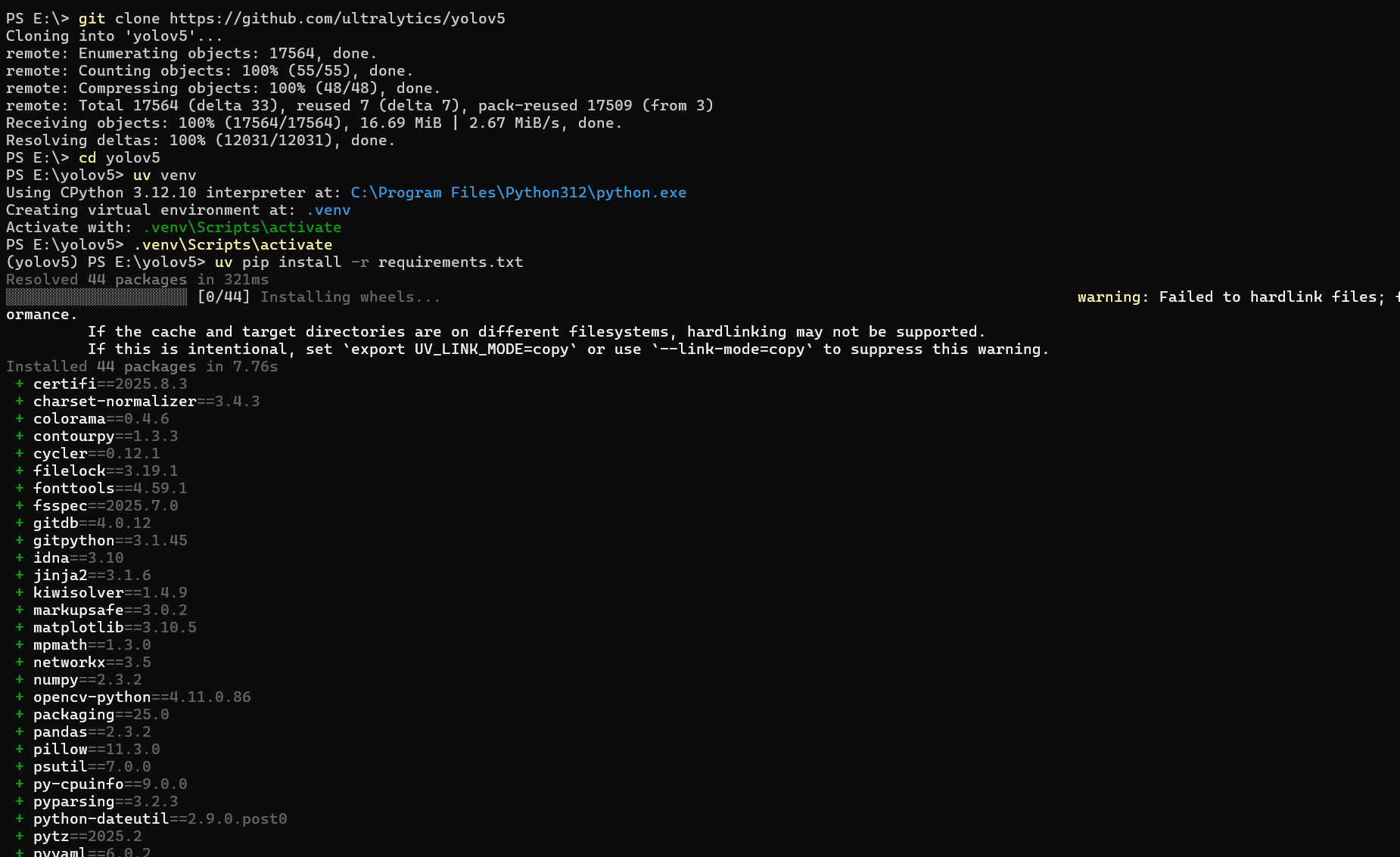
uv pip install -r requirements.txt如下图:
下载得到的Yolo5文件夹目录如下:
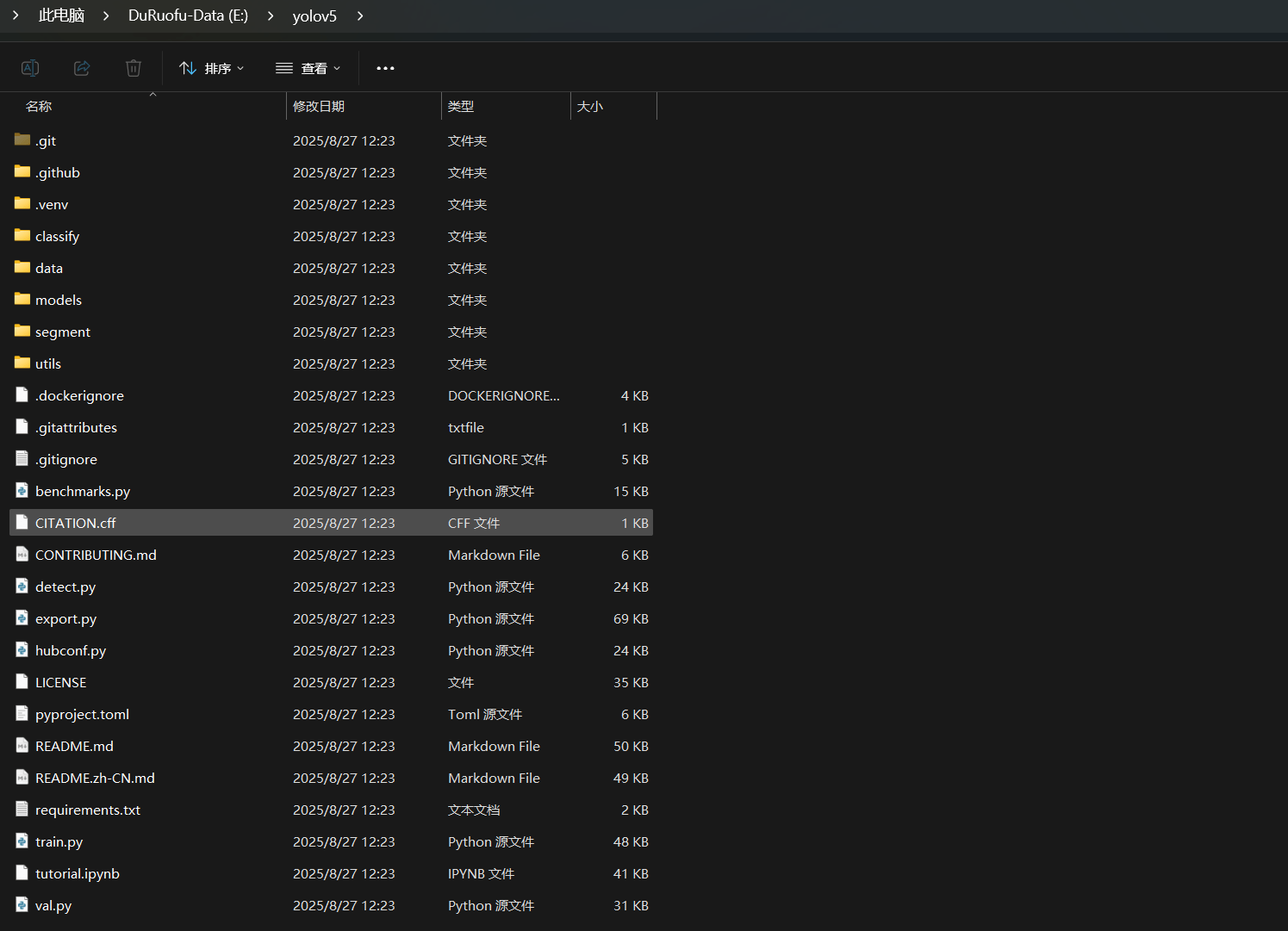
其中重要的文件解释如下、做了解即可:
yolov5/ # YOLOv5 项目根目录
├── classify/ # 分类任务相关代码
├── data/ # 数据集配置文件 (coco128.yaml 等)
├── models/ # 模型结构定义 (yolov5s.yaml 等)
├── segment/ # 分割任务相关代码
├── utils/ # 工具函数 (增强、NMS、日志、绘图等)
├── detect.py # 推理脚本 (图片/视频/摄像头检测)
├── train.py # 训练脚本
├── val.py # 验证脚本 (mAP 等指标)
├── export.py # 模型导出脚本 (ONNX, TensorRT, CoreML...)
├── hubconf.py # 允许 torch.hub.load 加载模型
├── benchmarks.py # 性能基准测试
├── requirements.txt # Python 依赖库清单
├── pyproject.toml # 项目配置 (构建/依赖信息)
├── LICENSE # 开源许可证 (AGPL-3.0)
├── README.md # 项目说明 (英文)
├── README.zh-CN.md # 项目说明 (中文)
├── CONTRIBUTING.md # 贡献指南
├── CITATION.cff # 学术引用文件
├── .git/ # Git 版本控制文件夹
├── .github/ # GitHub 配置 (CI/CD workflows)
├── .gitignore # Git 忽略规则
├── .dockerignore # Docker 忽略规则
├── .venv/ # 虚拟环境 (本地生成,不是源码自带)下面我们使用推理脚本 detect.py 来进行目标检测的初次尝试,官方文档里给的指令很清晰,有下面这些:
python detect.py --weights yolov5s.pt --source 0 # webcam
python detect.py --weights yolov5s.pt --source image.jpg # image
python detect.py --weights yolov5s.pt --source video.mp4 # video
python detect.py --weights yolov5s.pt --source screen # screenshot
python detect.py --weights yolov5s.pt --source path/ # directory
python detect.py --weights yolov5s.pt --source list.txt # list of images
python detect.py --weights yolov5s.pt --source list.streams # list of streams
python detect.py --weights yolov5s.pt --source 'path/*.jpg' # glob pattern
python detect.py --weights yolov5s.pt --source 'https://youtu.be/LNwODJXcvt4' # YouTube video
python detect.py --weights yolov5s.pt --source 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream这里我们使用第一种来加载我们的电脑摄像头:
使用命令(这里的--source 0 值摄像头编号,这里我有多个摄像头,我使用1号):
python detect.py --weights yolov5s.pt --source 1运行后效果如下:
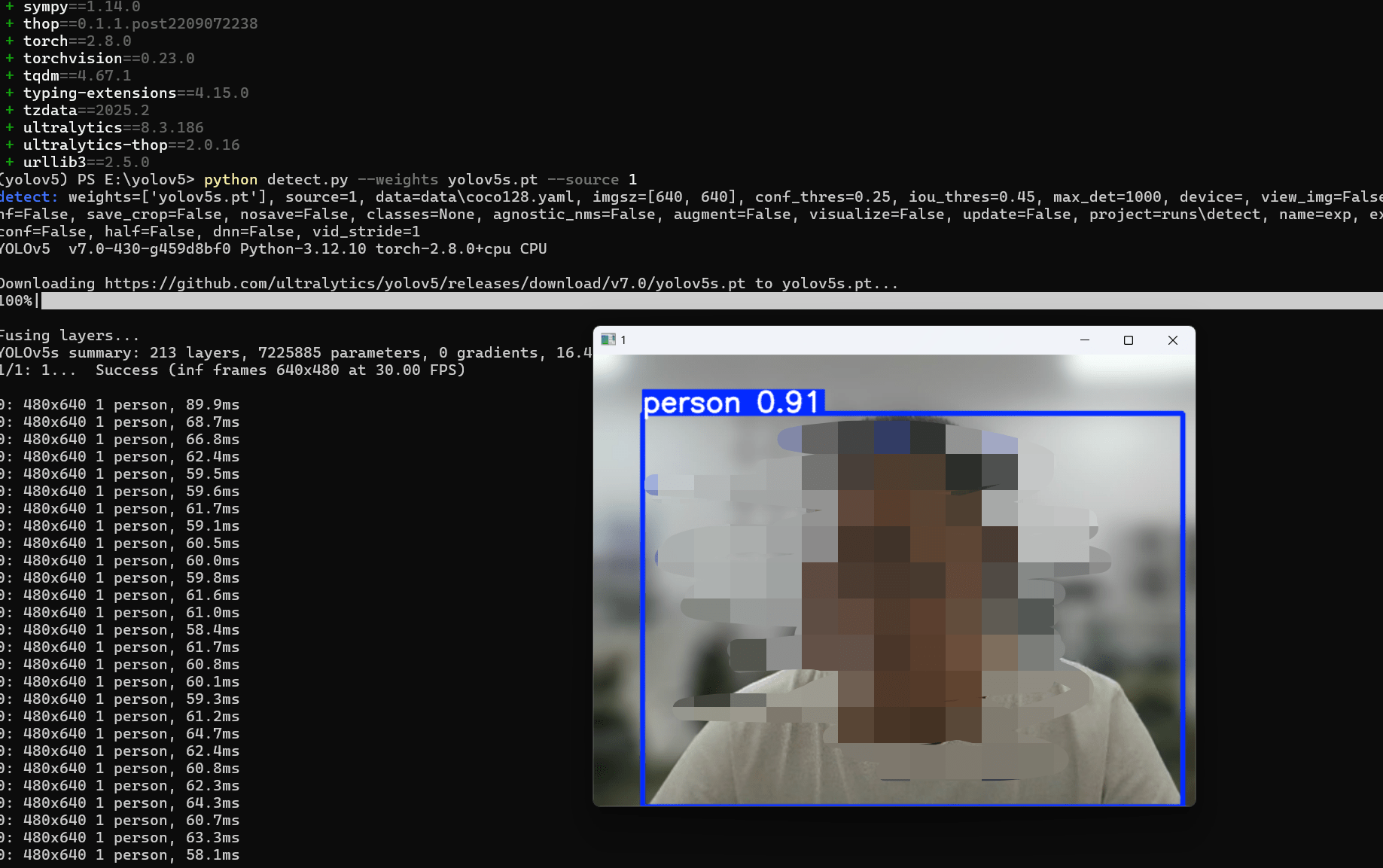
这样我们就完成了一次目标检测的尝试,我们也可以使用本地图片进行检测,将--source 的参数改为本地图片路径即可,比如--source img.jpg, 检测完成的结构会输出在目录下面的runs文件夹内,便于再次查看。
到这里我们就完成了Yolo的基本使用,下面我们尝试自行训练模型,来识别真正想识别的东西。
二、数据集概念和常见数据集结构
2.1 什么是目标检测数据集?
目标检测数据集包含两个核心部分:
- 图像文件:包含待检测目标的图片
- 标注文件:描述图像中目标的位置和类别信息
2.2 常见数据集格式
COCO 格式
- 特点:JSON 格式,适合复杂场景
- 结构:
dataset/ ├── images/ # 图像文件夹 │ ├── train/ │ └── val/ └── annotations/ # 标注文件夹 ├── instances_train.json └── instances_val.json
YOLO 格式
- 特点:每张图片对应一个 txt 标注文件
- 结构:
dataset/ ├── images/ │ ├── train/ │ └── val/ └── labels/ ├── train/ └── val/ - 标注格式:
class_id center_x center_y width height- 所有坐标都是相对于图像尺寸的比例值(0-1)
Pascal VOC 格式
- 特点:XML 格式,结构清晰
- 结构:
dataset/ ├── JPEGImages/ # 图像文件 ├── Annotations/ # XML标注文件 └── ImageSets/ # 数据集划分信息
2.3 常用公开数据集
| 数据集名称 | 类别数 | 图像数量 | 特点 |
|---|---|---|---|
| COCO | 80 | 330K | 复杂场景,多目标 |
| Pascal VOC | 20 | 20K | 经典数据集,入门首选 |
| Open Images | 600+ | 9M | 大规模,类别丰富 |
| ImageNet | 1000+ | 14M | 主要用于分类,也有检测版本 |
三、环境安装与配置
3.1 Python 环境准备
推荐使用 Python 3.8+ 版本:
# 创建虚拟环境
python -m venv yolo_env
# 激活环境 (Windows)
yolo_env\Scripts\activate
# 激活环境 (Linux/Mac)
source yolo_env/bin/activate3.2 安装 YOLOv5
方法一:从 GitHub 克隆(推荐)
# 克隆仓库
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
# 安装依赖
pip install -r requirements.txt方法二:使用 pip 安装
pip install ultralytics3.3 安装 YOLOv8
# 安装 ultralytics 包
pip install ultralytics
# 验证安装
yolo --version3.4 GPU 支持(可选但推荐)
如果有 NVIDIA GPU,安装 CUDA 版本的 PyTorch:
# 查看 CUDA 版本
nvidia-smi
# 安装对应版本的 PyTorch(以 CUDA 11.8 为例)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu1183.5 验证安装
创建测试脚本 test_yolo.py:
import torch
from ultralytics import YOLO
# 检查 PyTorch 和 CUDA
print(f"PyTorch 版本: {torch.__version__}")
print(f"CUDA 可用: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"GPU 设备: {torch.cuda.get_device_name(0)}")
# 加载预训练模型
model = YOLO('yolov8n.pt') # 自动下载
print("YOLO 模型加载成功!")运行测试:
python test_yolo.py四、快速开始:第一个 YOLO 检测
4.1 使用预训练模型进行检测
YOLOv8 示例
from ultralytics import YOLO
from PIL import Image
# 加载预训练模型
model = YOLO('yolov8n.pt') # n=nano, s=small, m=medium, l=large, x=xlarge
# 对图像进行检测
results = model('path/to/your/image.jpg')
# 显示结果
for result in results:
# 显示图像
result.show()
# 保存结果
result.save('output.jpg')
# 打印检测信息
for box in result.boxes:
print(f"类别: {model.names[int(box.cls)]}, 置信度: {box.conf:.2f}")YOLOv5 示例
import torch
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
# 检测图像
results = model('path/to/your/image.jpg')
# 显示结果
results.show()
# 保存结果
results.save('output/')
# 获取检测结果
print(results.pandas().xyxy[0]) # 边界框坐标和置信度4.2 批量检测
from ultralytics import YOLO
import os
model = YOLO('yolov8n.pt')
# 检测文件夹中的所有图像
image_folder = 'path/to/images/'
for filename in os.listdir(image_folder):
if filename.lower().endswith(('.jpg', '.jpeg', '.png')):
image_path = os.path.join(image_folder, filename)
results = model(image_path)
# 保存结果
results[0].save(f'output/{filename}')
print(f"已处理: {filename}")4.3 视频检测
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
# 检测视频
results = model('path/to/video.mp4')
# 保存检测结果视频
for result in results:
result.save('output_video.mp4')五、训练自定义模型
5.1 准备数据集
数据集目录结构
custom_dataset/
├── images/
│ ├── train/
│ └── val/
├── labels/
│ ├── train/
│ └── val/
└── dataset.yaml创建 dataset.yaml
# dataset.yaml
path: ./custom_dataset # 数据集根目录
train: images/train # 训练图像路径
val: images/val # 验证图像路径
# 类别数量
nc: 3
# 类别名称
names: ['person', 'car', 'bicycle']5.2 开始训练
YOLOv8 训练
from ultralytics import YOLO
# 加载预训练模型
model = YOLO('yolov8n.pt')
# 开始训练
results = model.train(
data='dataset.yaml', # 数据集配置文件
epochs=100, # 训练轮数
imgsz=640, # 图像尺寸
batch=16, # 批次大小
name='custom_model', # 实验名称
device=0 # GPU 设备 (0 表示第一个GPU,'cpu' 表示使用CPU)
)命令行训练
# YOLOv8
yolo train data=dataset.yaml model=yolov8n.pt epochs=100 imgsz=640
# YOLOv5
python train.py --data dataset.yaml --weights yolov5s.pt --epochs 1005.3 模型评估
# 评估模型性能
metrics = model.val()
print(f"mAP50: {metrics.box.map50}")
print(f"mAP50-95: {metrics.box.map}")5.4 使用训练好的模型
# 加载自定义训练的模型
model = YOLO('runs/detect/custom_model/weights/best.pt')
# 进行预测
results = model('test_image.jpg')
results[0].show()六、模型部署与优化
6.1 模型格式转换
导出为 ONNX 格式
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
# 导出为 ONNX
model.export(format='onnx')导出为其他格式
# 支持的格式
formats = ['onnx', 'torchscript', 'tensorflow', 'tflite', 'coreml']
for fmt in formats:
model.export(format=fmt)6.2 推理优化
使用 TensorRT 加速(NVIDIA GPU)
# 安装 TensorRT
pip install nvidia-tensorrt
# 导出 TensorRT 模型
yolo export model=yolov8n.pt format=engine device=0使用 OpenVINO 加速(Intel CPU)
# 安装 OpenVINO
pip install openvino
# 导出 OpenVINO 模型
yolo export model=yolov8n.pt format=openvino七、常见问题与解决方案
7.1 安装问题
问题:pip install 速度慢 解决:使用国内镜像源
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple/问题:CUDA 版本不匹配 解决:检查 CUDA 版本并安装对应的 PyTorch
nvidia-smi # 查看 CUDA 版本
# 访问 https://pytorch.org/ 获取安装命令7.2 训练问题
问题:显存不足 解决:
- 减小 batch size
- 使用更小的模型(如 yolov8n)
- 减小图像尺寸
问题:训练速度慢 解决:
- 使用 GPU 训练
- 增加 workers 数量
- 使用混合精度训练
7.3 检测效果问题
问题:检测精度低 解决:
- 增加训练数据
- 调整数据增强参数
- 使用更大的模型
- 增加训练轮数
问题:检测速度慢 解决:
- 使用更小的模型
- 降低输入图像分辨率
- 使用模型量化或剪枝
八、进阶学习资源
8.1 官方资源
- YOLOv5 GitHub:https://github.com/ultralytics/yolov5
- YOLOv8 文档:https://docs.ultralytics.com/
- Ultralytics Hub:https://hub.ultralytics.com/
8.2 学习建议
- 从预训练模型开始:先熟悉基本使用,再尝试训练
- 小数据集练手:使用少量数据快速验证流程
- 逐步优化:从基础配置开始,逐步调优参数
- 关注社区:加入相关技术群组,获取最新信息
8.3 实践项目推荐
- 人脸检测:使用 WIDER FACE 数据集
- 车辆检测:使用 KITTI 数据集
- 行人检测:使用 CityPersons 数据集
- 自定义场景:收集特定场景数据进行训练
总结
YOLO 作为目标检测领域的经典算法,具有速度快、精度高、易部署的特点。通过本指南,你应该能够:
✅ 理解 YOLO 的基本原理和发展历程 ✅ 掌握常见数据集格式和结构 ✅ 完成环境安装和配置 ✅ 使用预训练模型进行检测 ✅ 训练自定义模型 ✅ 进行模型部署和优化